TIP
乍一看这标题什么鬼嘛?PaddlePaddle 不是一个深度学习框架嘛?这还能强行变可爱嘛?嘿嘿,怎么说呢,目前 Paddle 相对于很多大型开源项目在代码规范上是有一定欠缺的,之前也有尝试过参与一些相关的优化,但如此庞大的一个 Codebase 并不是说随随便便改改就好的啦,所以,便有了本「计划」。(嘿嘿,咱的 moefyit (opens new window) 计划可以在 Paddle 社区开展了呢~)
# 常见开发工作流及工具
# 开发工作流
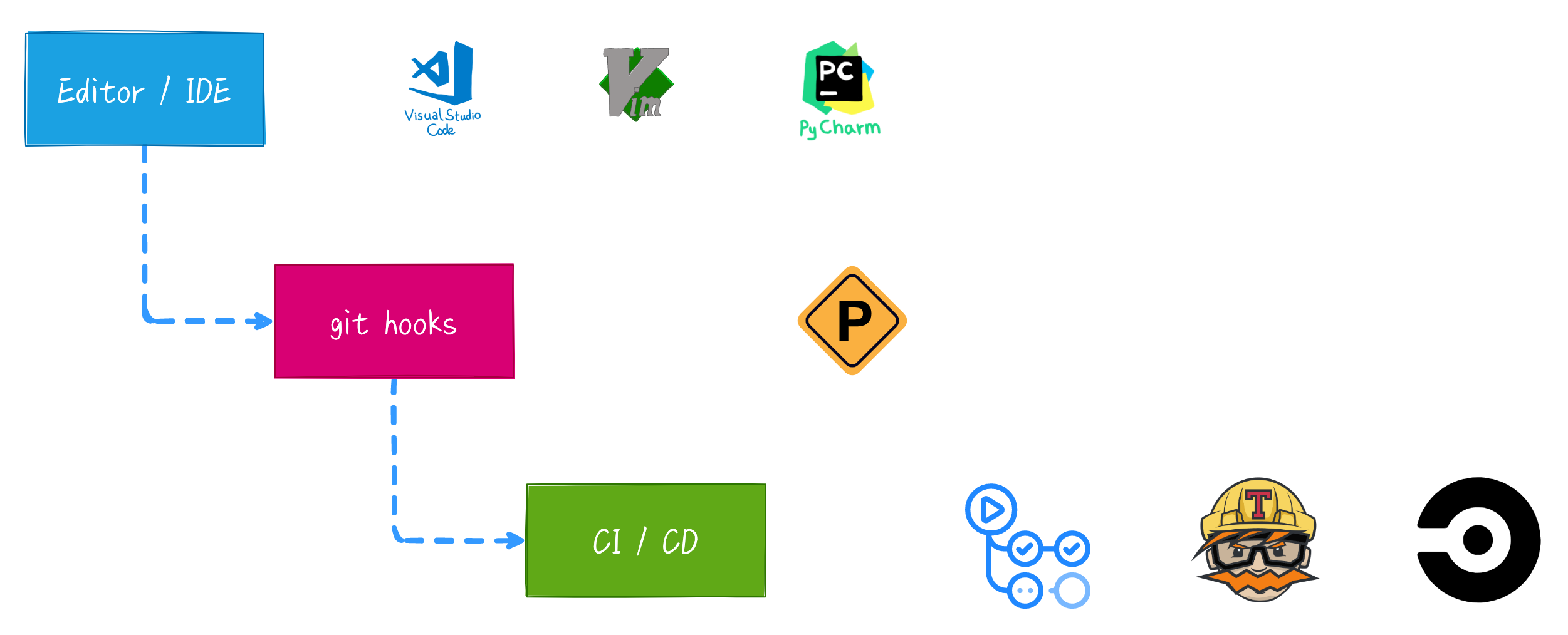
想必熟悉开发流程的同学们对工作流中的几个阶段也都非常了解了。一般情况下我们首先会在编辑器或者 IDE 上开发,然后通过 git 来进行一系列源代码的管理,之后推送到远程仓库,往往最后会触发相关的 CI/CD 来进行一些自动化测试、部署等操作。
我们在编辑器上进行开发时,往往会配置一些 Linter 或者 Formatter 工具,它们可以为我们及时地提供错误反馈及建议,使我们能够在开发过程中就解决大多数的格式等问题。当然,我们也可以手动在 Terminal 运行相应的 CLI 工具,来手动进行一些格式化等操作。
之后利用 git 进行 commit、push 等等操作时,由于 git 在这些生命周期是可以注入一些 hook 的,因此我们也可以利用这个阶段来完成一些自动格式化、代码检查等操作。目前各个生态也都有比较成熟的 hook 管理工具,比如 Python 生态下的 pre-commit (opens new window),Node.js 生态下的 husky (opens new window) 等等。利用这些工具可以轻松配置一些实用的 hook,提高工作流的自动化程度。
最后就是 CI 啦,CI 是整个工作流的最后一步,这一步往往有最完整的代码检查,这样即便开发者本地编辑器没有进行相关配置,或者本地没有安装 pre-commit,在这一步都能够检查出来,保证了合并到主线上的代码是没有相关问题的。
# Python 常见开发工具链
相比于一些新兴的语言来说,Python 的工具链一直处于非常落后的状态,Python 官方提供的工具链是非常不完善的,或者说是不「现代」的。因此可以看到 Python 的项目结构往往配置地形态各异,也使得参与开发的人需要对项目有一定熟悉程度才能上手。这里会简单介绍一些常见的工具。
如果要说完整的工具链的话,那么环境、依赖管理工具、Linter、Formatter、测试套件这些都是必不可少的啦。不过本文的关注的重点是 Linter 和 Formatter。
# Formatter
Formatter 主要用于自动格式化代码,使得项目代码风格统一,避免项目协作时因为格式的调整而出现一些没必要的改动。合格的 Formatter 是不会对代码语义进行任何更改的,可以认为格式化是一个非常安全且可靠的操作,因此我们可以放心地在任何时刻运行它,而不必担心代码修改后出现问题。
目前常见的格式化工具包括了 yapf、black、autopep8 等,还有一些只针对某些特定场景进行格式化的工具,比如 isort,就是只格式化 import 语句的顺序的。
yapf 是 Google 开发的格式化工具,它非常像 clang-format,有着非常多的配置项,可以配置出各种各样想要的代码风格。但是 yapf 的格式化力度并不高,同一段代码经过调整后它可以格式化出好多种代码格式。
black 是一个不妥协的格式化工具,有点像 prettier 这样的 JS/TS 格式化工具,它可以保证相同的代码格式化出来的结构是一致的,不会因为代码稍微调整出现代码风格的突变,在视觉上也非常的统一。唯一可能的缺点是因为它基本不可配置,因此如果你不喜欢 black 格式化后某一段代码的风格,基本是没办法调整的,除非使用 # fmt: off 禁止该区域代码的格式化。
autopep8 是一个非常简单的格式化工具,没啥格式化力度,也正如其名字,就是个自动修复 PEP 8 (opens new window) 中所描述的代码风格问题的工具而已。在某些问题的修复方案上甚至会改变代码的语义,因此我认为它不算是「合格」的格式化工具。
# Linter
Linter 主要用于给开发者提示代码中存在的格式问题、语法问题和一些潜在的逻辑问题。与 Formatter 不一样的是,Linter 往往是不进行自动修复的,最多只会给出一个修改建议,提示开发者手动对问题进行修复。当然,由于 Linter 会给出一些潜在的逻辑问题,对于这些问题也只能手动修复,当然,Linter 相比于 Formatter 所拥有最大的价值也在于提示这些逻辑问题。
目前常见的 Linter 工具主要包含了 Flake8、Pylint 等,此外还有些静态类型检查工具,比如 Mypy、Pytype、Pyright 等。
Flake8 是 pycodestyle、pyflakes 和 mccabe 三个工具的集合,它们分别用于检查代码风格、语法错误和循环复杂度。此外,Flake8 还支持插件,这使得 Flake8 可以做到各种各样的检查项。
Pylint 我没有用过,也没有去调研,因此不做评判。
Pyright 是 VS Code 推荐的扩展 Pylance 的后端,它不仅仅可以提供静态类型检查,而且还能提供少许代码风格和代码逻辑上的检查,并且凭借着 Pylance 扩展,为 VS Code 提供了非常棒的 Python 开发体验。
# 个人推荐
我个人非常喜欢使用 black + isort + VS Code Pylance 扩展的组合,black 在自动格式化的过程中可以解决大多数格式问题,isort 为 import 顺序进行自动重排,而 Pylance(Pyright)则会给出一些类型上、逻辑上的建议,基本上可以满足大多数日常开发需求。
前段时间尝试在一个我长期使用该组合进行开发的项目中尝试使用 Flake8 进行检测,结果仅仅只有不到 10 个 Flake8 问题,而且这些问题基本上都是一些无用的建议,即便引入 Flake8,我也只会在那些地方加上 # noqa 而已。
如果要说环境、依赖管理工具和测试套件的话,我比较推荐 Poetry 和 pytest,但这里就不赘述了。
# 将工具引入工作流的各个阶段
当然,这些工具都是要用的嘛,用的时机也就是之前所说的那几个阶段啦~
# Editor / IDE
由于 Linter 往往会给出各式各样的提示,在开发中出现问题的频率是非常高的,因此在编辑器中配置 Linter 来进行实时提示往往是非常重要的,这样可以给开发人员一个最及时的反馈。
Formatter 往往则并不需要那么高运行的频率,一般情况下配置成在保存时进行格式化即可。
如果编辑器配置的好的话,能够给开发人员最佳的开发体验。但由于每个人的喜好不同,选择的编辑器往往也不一样,因此编辑器的配置统一也是一件非常麻烦的事情,在文档中提供相关说明是非常必要的。
# git hooks
在 git 生命周期里,pre-commit 是最常使用的一个生命周期阶段,在这个阶段衍生出各式各样的工具。如果是 Python 的话,pre-commit 是不二选择,pre-commit 有着非常丰富的生态,而且允许通过非常简单的方式自定义一个新的 hook。我们可以通过 pre-commit 添加各式各样的检查,比如 Linter 的问题检查、Formatter 的是否已经格式化过的检查等等。
# CI / CD
CI 本质也很简单,就是一个统一的环境,运行各种各样的命令,因此我们当然可以配置 Linter、Formatter 等工具来进行检查。当然,CI 往往还会包含一些比如单元测试、文档部署等的一些操作。
如果一些工具已经集成在 pre-commit 里了,那么我们也可以直接在 CI 上运行 pre-commit,以保证这些工具都是可以检查通过的。
# 配置方式
这里各种各样的工具往往都是有一些配置项的,比如 Linter 所需要检查的错误项、Formatter 的最大行宽等,如果我们在每个阶段分别对这些工具配置的话,很容易造成不同阶段工具使用方式的不一致。比如编辑器里设置了 black 最大行宽 120,而 CI 里设置了 80,这样就会造成 CI 检查不通过的情况。
不过大多数工具都是支持读取配置文件的方式的,我们可以将配置文件放到项目的根目录,这样在项目中运行这些工具时就会自动读取这些配置文件,不用再担心配置不一致的问题了。
由于现在大多数工具都支持在 PEP 518 (opens new window) 提出的 pyproject.toml 里进行配置,因此也是非常建议将这些工具的配置都放在这一个文件中的。当然,除了 Flake8 (opens new window)。
除此之外,个人非常推荐一个跨编辑器配置文件 .editorconfig (opens new window),这个文件可以配置编辑器的一些通用配置,比如缩进、换行符等,这样就不用考虑各式各样编辑器下格式配置不统一的问题了。我个人也是非常庆幸在刚刚接触开源时就了解到了这个配置文件,让我在这几年开发过程中基本没有遇到格式上的问题,因为一切都在源头(编辑器)上就解决了。
# 这些工具咋实现的?
# 直接在纯文本上做
前面说了这么多的工具,不过这些工具都是如何实现的呢?首先考虑一种非常简单的方式,文本搜索和替换。虽然是一个最简单的方式,但也有不少工具也确实是这么做的,比如 end-of-file-fixer (opens new window)、remove-tabs (opens new window) 这些简单的代码格式修复工具等。
一些稍微复杂的需求的话当然是可以利用正则来进行搜索替换的啦,比如我之前做的自动在中英文间加空格的 insert-whitespace-between-cn-and-en-char (opens new window) 就是使用正则实现的。
但如果有些更加复杂的需求的话,可能就需要手写一些复杂的规则进行处理了,但一般情况下这种需求并不多,而且大多数文本都是有一定的语法规则的,这些拥有语法规则的文本直接在 AST 上处理是更好的方式。
# 进一步在词法单元上进行分析
如果一个工具需要专门分析某种语言一些格式上的问题的话,在词法上分析 Token Stream 是比较合适的,不过这样的需求一般也不会太多,目前我了解到的也只有 pycodestyle 这一个工具使用的是这种方式。大多数工具都是在进一步经过语法分析处理成的语法树上进行操作的。
# 再进一步直接在 AST 上操作
经过语法分析后,我们就可以得到语法树啦。语法树包含具象语法树和抽象语法树(AST,Abstract Syntax Tree),抽象语法树相比于具象语法树省略了部分细节,因此在处理时会更加方便。这里将之前我在进行单测报错信息优化 (opens new window)时的一个简单的例子来说明一下 AST 的结构。
首先说明下当时的一个需求,是将 self.assertTrue(np.allclose(x, y, rtol=rtol, atol=atol), msg=msg) 形式的代码处理成 np.testing.assert_allclose(x, y, rtol=rtol, atol=atol, err_msg=msg) 形式的代码。乍一看可能会想到使用正则进行处理,不过稍微一想就会发现有很多坑,比如括号匹配的问题。但既然是处理符合 Python 语法的文本,我们直接交给最专业的 Python 语法分析工具肯定是最合适的啦~
利用 Python built-in 的 ast 模块就可以将一段 Python 文本代码处理成一个 AST 结构,比如下面这段 Python 代码,在经过处理后即可得到一棵如下图所示的 AST:
self.assertTrue(
np.allclose(
res[0],
feed_add,
rtol=1e-5),
msg='blabla((((()()((xxxdfdf('
)
2
3
4
5
6
7

我们可以从叶子结点上隐约看出原来的文本代码结构。
对 AST 进行处理会比直接对文本处理方便得多,比如我们可以通过遍历这个 AST 来找到我们需要的模式,然后对部分结点进行替换重构,形成新的 AST。这个过程中使用的往往是访问者模式,由于之前已经说过访问者模式了,这里就不赘述了。在 AST 上处理过后,我们最后还是要将新的 AST 转换成文本代码,这样就完成了整个处理过程。
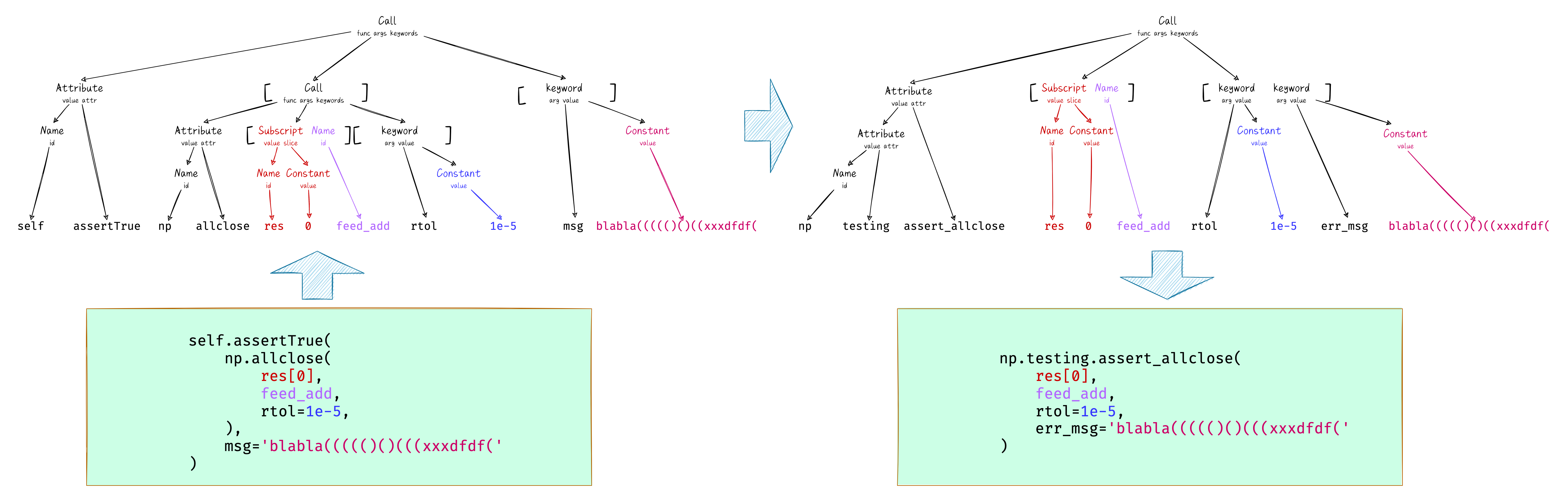
整体流程也如上图所示,是一个从文本到 AST,经过若干处理后再转回文本的过程。
利用 AST 的工具不在少数,formatter 自不必说,linter 也有很大一部分也是在 AST 上进行语法结构匹配和分析的。
# 一个推荐的工具 ast-grep
前面也说了,如果想要利用 AST 进行搜索替换的话,往往需要先将代码转换成 AST,并同时需要匹配的模式转换为 AST 进行匹配,之后再经过若干处理步骤后转回文本,整体做起来非常繁琐。
在做单测报错信息优化的时候我就有写一个基于文本模式进行搜索替换的工具的想法。当时的设想是能够传入一段文本和文本的模式,提供类似正则的语法进行搜索替换,避免手写 AST 处理代码。不过因为暂时没有更多的需求,就先搁置下来了。
不过非常巧的是 HerringtonDarkholme (opens new window) 就在前段时间开源了一个使用 Rust 写的基于 AST 的文本搜索替换工具 ast-grep (opens new window),一些用法和我之前的想法基本上一致,当我看到这个工具的名字的时候其实就确定了。
这个工具使用方式也是非常简单,直接传入待搜索的文本模式和需要输出的文本模式即可,比如下面这个例子:
cargo run -- --pattern 'self.assertTrue(np.allclose($A, $B, $$$REMAIN_ARGS), msg=$MSG)' --rewrite 'np.testing.assert_allclose($A, $B, $$$REMAIN_ARGS, err_msg=$MSG)' --lang py ut.py

不过这个工具还处于非常早期的状态,问题还是蛮多的,我刚刚开始尝试这个工具的时候甚至对 Python 语言支持是有一点点问题的,因此就去提了个 PR 修复了下~
此外,HerringtonDarkholme 还为 ast-grep 设计了一些巧妙的功能,比如配置一些规则,以起到 Linter 的作用,不过由于目前还只能做到简单的模式匹配,因此还是有很多限制的。
# 如何引入新工具?
# 解决存量代码中的问题
诶?说了这么多,好像都和 Paddle 没什么关系嘛!更别说让 Paddle 更可爱了!了解工具原理有啥用捏?难道我们还真要实现个工具不成?
嘿嘿,也许真的会有些需求是需要我们自己动手写各种各样的工具的,比如我们有一些定制化的重构需求,或者在引入新的工具的时候。
如果想要引入新的工具的话,当前代码库中的现存问题一定是要考虑的,不然如果仅仅引入工具而不去修复存量问题的话,之后的开发者在改动一个文件后可能要对这个文件中所有存量问题都解决一番,这样不仅浪费了开发者的时间,还会使得 review 时出现很多无关改动。
如果引入工具是个 Formatter 的话,那么自然是直接一键格式化即可。但如果引入的是 Linter 的话,我们可以首先看看有没有一些现成的修复工具,当然,有很多问题的修复其实是不可靠的,有可能修改代码的语义,因此我们还是需要人工去 review 修复后的代码。当然,如果没有相关工具的话,就只能自己编写工具或者手动进行修复了。
# 配置新工具,引入到工作流中的几个阶段
在解决存量问题后,就可以在代码库中对工具进行配置了,也正如最开始所说的,即将工具配置到工作流的各个阶段即可。
对于比较成熟的工具,我们直接利用它们提供的 pre-commit-hooks 即可同时将其引入到 pre-commit 和 CI 两个阶段,在编辑器阶段的话,最好提供说明文档来告知开发者所使用的工具及相关的配置指南。
如果有一些使用频率不高的检查项的话,我们直接在 CI 上写一个检查脚本即可。
# 那,我们都可以做些什么呢?
能做的可太多了……比如目前我正在进行 Flake8 引入 (opens new window)的计划,在这个过程中我也有计划同时引入 isort 等工具。由于目前 Paddle 使用的格式化工具 yapf 存在许多问题,而且可能会存在大量 Flake8 错误码需要手动修复,因此目前也有计划将 Paddle 的格式化工具从 yapf 切换到 black。
此外,Paddle 中文文档目前使用的是 reStructureText 编写的,目前存在各种各样的格式问题,其实对于这种文档来说 rst 并不是一种好的存储格式,我和笠雨聆月 (opens new window)也有一个重写文档生成流程的初步计划,当然,至于什么时候开始做什么时候能做完,那我只能说:「咕咕咕」(๑><๑)
我在之前还有尝试给 Paddle 开发一个 PEP 561 (opens new window) 中描述的 stub only 的 package (opens new window),这对于 Paddle 目前缺失的类型提示也是非常有帮助的,不过这个包目前也是在开发的早期,啥时候能用我也不知道……当然,如果将来有机会我是希望 Paddle 内部能直接集成类型提示的,这样不仅能够提供最好的类型提示效果,而且也能为 Paddle 开发者提供类型提示和验证效果,大大减少一些类型错误的发生。
# 结束了?
想多了诶!这才哪到哪啊,这才是《让 Paddle 更可爱》第一期《开发者体验提升计划》中的一小部分好吧~
开溜~