TIP
随着深度学习的快速发展,传统神经网络结构的弊端也日益凸显,无论是 还是 ,处理的数据仅限于欧式空间,而对于拓扑结构的数据就手足无措了,然而我们我们生活的世界更多的数据还是拓扑结构数据,至于表示拓扑结构的最好方法,非图莫属了,那么如何利用图的结构进行学习呢,下面让我们一探 的究竟
- 预备知识
- 传统 的连接结构
- 基本卷积方式
- 开发环境
python 3.6
- 格式使用
Jupyter Notebook,Out部分放于块尾注释中
TIP
本文不深究公式细节,主要是为了更轻松地从传统神经网络过渡到 ,主要代码及结构参考 Ref1 ,文字部分主要为自己的理解,如果有不当之处,还请指正
import numpy as np
import networkx
from matplotlib import pyplot as plt
def ReLU(x):
return (abs(x) + x) / 2
2
3
4
5
6
# GCN 的输入
与传统网络不同的是, 的输入并不只是特征,它额外包含了图中各个结点之间的关系,那么关系用什么表征呢?显而易见,邻接矩阵是一个非常简单易行的表示方法,这里使用邻接矩阵 来表示各个顶点之间的关系,显然
相应地,各个顶点的特征使用矩阵组织起来就好啦,这里使用 表示输入层特征矩阵, 表示第 隐藏层特征矩阵,当然 ,显然
表示第 层的特征维度, 表示顶点个数
# 与 CNN 的相似性
我们知道,普通 的卷积是同时对空间与通道进行卷积,而 和 所使用的深度可分离卷积是对空间卷积与通道的全连接进行的分离,而且深度可分离卷积确实比普通卷积有着更少的参数,在等量参数下,深度可分离卷积有着更好的效果
深度可分离卷积将一个卷积层分成两个子层,第一步是对每个通道进行空间上的卷积,各个通道独立操作,第二步是对通道进行线性组合,也就是传统神经网络所做的事,那么对于一个图数据,是否也可以这样做呢?
假如一张图也是可以卷积的,那么我们首先对它进行卷积,之后对特征进行全连接,这便是 的基本结构了
相应的,特征的维度便是传统网络的某一层结点单元数,特征维度的变换便是各层结点之间的全连接,当然这也说明了为何 ,当然, 的所有参数都用在了两层之间全连接上了,图卷积并无参数(区别于 卷积核需要参数)
# 图卷积网络层的构建
首先考虑一种非常非常简单的传播方式
为激活函数, 为第 层的参数,,另外值得注意的是,这里的乘法均为矩阵乘法,仅仅看 便可以知道这种变幻的合理性了, ,但是究竟为什么这样会有效呢?
下面考虑一个非常简单的示例,图结构如下(),

首先写出邻接矩阵 ()
A = np.matrix([
[0, 1, 0, 0],
[0, 0, 1, 1],
[0, 1, 0, 0],
[1, 0, 1, 0]
],dtype=np.float64
)
2
3
4
5
6
7
然后写出表示输入特征的 () (这里输入特征维度为 )
X = np.matrix([
[i, -i] for i in range(A.shape[0])
], dtype=np.float64)
X
# matrix([[ 0., 0.],
# [ 1., -1.],
# [ 2., -2.],
# [ 3., -3.]])
2
3
4
5
6
7
8
应用图卷积
A * X
# matrix([[ 1., -1.],
# [ 5., -5.],
# [ 1., -1.],
# [ 2., -2.]])
2
3
4
5
我们可以发现,原始特征在经过第一步图卷积之后在图上发生了传播,比如顶点 1 ,聚合了邻居 2 和 3 的特征
如果存在从 到 的边,则 是 的邻居,也即有向图沿着箭头的反方向传播,无向图沿着边传播
但是这样就会产生两个问题
首先,每个顶点特征在传播后自身的信息会丢失,为了避免这一问题,可以通过在图上增加自环来解决,具体方法就是在 的基础上增加单位矩阵 ,得到的修正结果为
I = np.matrix(np.eye(A.shape[0])) (A + I) * X # matrix([[ 1., -1.], # [ 6., -6.], # [ 3., -3.], # [ 5., -5.]])1
2
3
4
5
6另外还有一个问题就是,各个特征在聚合的过程中传播的次数取决于顶点度的大小,度大的顶点会使得特征的在整体表征所占权重更大,这可能会引发梯度消失或梯度爆炸,一种简单的想法就是对度进行归一化,至于归一化的方法,可以使用 ,论文中使用 ,道理都一样,本文暂时不涉及后者
为矩阵 的度矩阵
首先写出获取一个矩阵的度矩阵的函数,并求得矩阵 的度矩阵
def get_degree_matrix(A): D = np.array(np.sum(A, axis=0))[0] D = np.matrix(np.diag(D)) return D D = get_degree_matrix(A) D # matrix([[1., 0., 0., 0.], # [0., 2., 0., 0.], # [0., 0., 2., 0.], # [0., 0., 0., 1.]])1
2
3
4
5
6
7
8
9
10下面求出归一化的邻接矩阵
D**-1 * A # matrix([[ 0. , 1. , 0. , 0. ], # [ 0. , 0. , 0.5, 0.5], # [ 0. , 0.5, 0. , 0. ], # [ 1. , 0. , 1. , 0. ]])1
2
3
4
5很明显,邻接矩阵在度大的方向减小了链接权重(除以对应的度)
D**-1 * A * X # matrix([[ 1. , -1. ], # [ 2.5, -2.5], # [ 0.5, -0.5], # [ 2. , -2. ]])1
2
3
4
5相应地,聚合时传播效果也是归一化的结果
下面,将上述两个问题结合起来,首先求得 ,之后对 进行归一化,当然, 是 的度矩阵
A_hat = A + I
D_hat = get_degree_matrix(A_hat)
D_hat**-1 * A_hat * X
# matrix([[ 0.5, -0.5],
# [ 2. , -2. ],
# [ 1. , -1. ],
# [ 2.5, -2.5]])
2
3
4
5
6
7
至于后面的参数,乘一下就好了,然后加上激活函数便完成一层图卷积网络层了
W = np.matrix([
[1, -1],
[-1, 1]
])
ReLU(D_hat**-1 * A_hat * X * W)
# matrix([[1., 0.],
# [4., 0.],
# [2., 0.],
# [5., 0.]])
2
3
4
5
6
7
8
9
# 何谓卷积
回顾传统卷积,可以看做是每个卷积核处,不同像素点的特征聚合于卷积核中心处而已
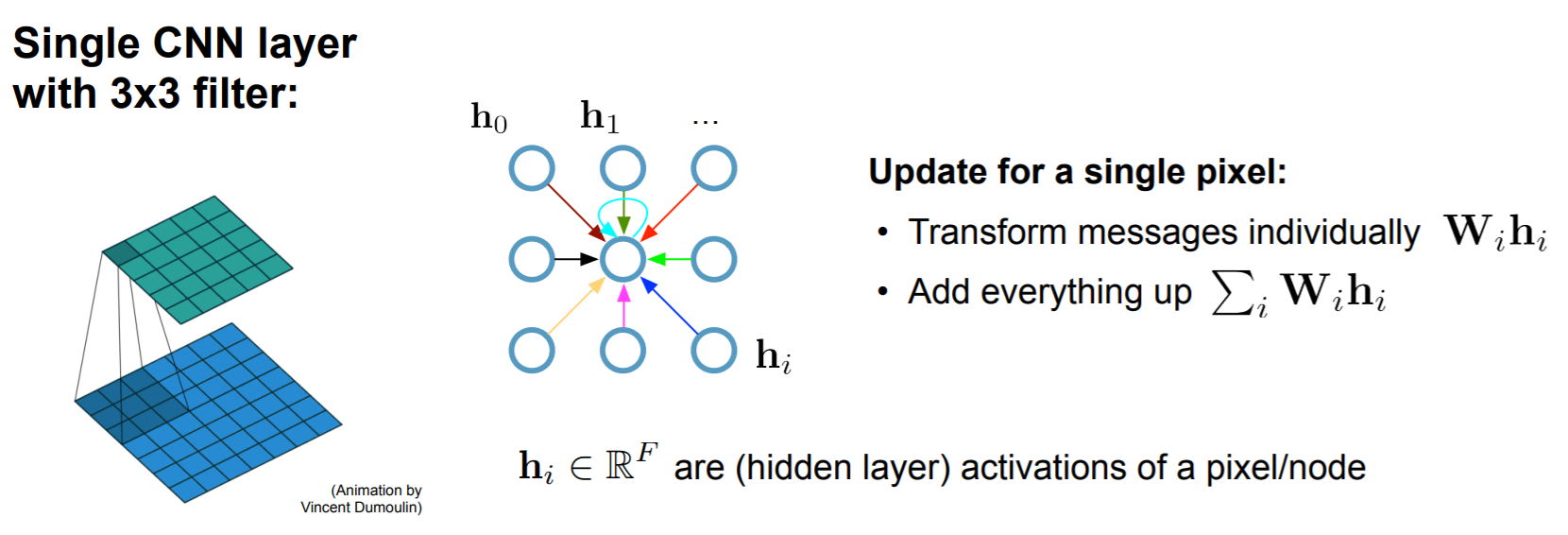
而图卷积,是沿着图的边,将邻居的特征聚合于自身
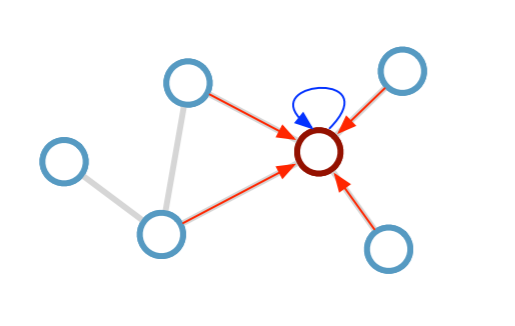
本图为无向图,若为有向图,聚合方向沿着箭头的反方向
当然,前者发生在欧式空间,后者是在拓扑结构上,所谓卷积,可以说是相邻结点的一次信息聚合,而信息的聚合,Ref3 (opens new window)一文中首先使用了温度场模型的热量传播进行比拟,之后推到图模型,由浅及深地进行了解释
对于一个连续的模型, 时刻的结果就是 ,而一个离散的结构,每一时刻的结果都与前一时刻相关联,每一位置的结果都与周围位置相关联,在求得了前一时刻各位置的结果后,下一时刻任何一个位置都可以求得,每一个位置的结果取决于其相邻结点,具体关系可对原来的连续模型下的公式进行离散化,化微分为差分,便可得到相邻结点传播公式
聚合针对某一结点,传播针对整个结构 另外,由于本学期有一门专业课恰好学习并实践温度场模型的有限差分模拟,所以看到这篇文章倍感亲切~
# 图卷积的优点
图卷积是在传统网络的基础上增加了图的结构,增加的信息当然不是毫无用处,因为图的存在,使用随机初始化的参数便可完成初步的聚类,而且只需要较少的标签便可完成学习,因此 也被称为是一种半监督学习方式
# 总结
整个图卷积网络层,可以分为两步,第一步是图卷积,第二步是层与层之间的连接
前者使用邻接矩阵 ,使得特征沿着图的边进行传播,得到 ,考虑到自环问题和归一化问题的话,改为 或者 即可
后者使用链接权重 ,与传统网络并无不同,其 依然为 (这里 和 用来表示层的输入与输出),之后激活一下就好啦
总的来说,图卷积不过是在前层特征计算完之后再整张图上传播一下(第一步),之后和传统网络并无区别