TIP
近期在做一些 Python 3.11 的适配工作,结果 Python 3.11 的改动实在是太多了,针对一个一个问题解决并不利于理解 Python 3.11 改动的本质,因此这里稍微花了点时间来调研和整理 Python 3.11 的核心变化。
# Faster CPython——不断加速的 CPython
自从几年前 Faster CPython (opens new window) 发起以来,CPython 的开发者们一直致力于提升 CPython 的性能,而 Python 3.11 则是 Faster CPython 的一个里程碑,在 pyperformance (opens new window) benchmark 上平均比 Python 3.10 快 25%。
从 Python 3.11 Release Notes - Faster CPython (opens new window) 一节中我们能找到 Python 3.11 中主要的加速点,Release Notes 中将其分为「启动加速」和「运行时加速」两部分。
「启动加速」主要就是将核心模块进行「frozen」,我们可以通过分别打印 Python 3.10 和 Python 3.11 的部分核心模块来对比:
import os
print(os)
# Output in Python 3.10
# <module 'os' from '/path/to/os.py'>
# Output in Python 3.11
# <module 'os' (frozen)>
2
3
4
5
6
7
8
可以看到 Python 3.11 的 os 模块已经是 frozen 的了。
关于「运行时加速」,主要包含如下几点:
- 更加轻量和 Lazy 的 frame。简单来说就是 Python 3.11 的 frame 是更加精简的数据结构,其中去掉了调试信息和异常堆栈,因为在大多数情况下这些信息是没有必要的,如果需要原来的 FrameObject 则可以 lazy 地创建,而异常信息 (opens new window)则是在编译时通过分析生成了(CodeObject 的
co_exceptiontable),运行时则是近乎零成本(只需要在发生异常时查表,而不需要维护异常堆栈)。 - Inline 函数调用。在 Python 3.11 之前,每发生一次 Python 函数调用的同时也会创建一个 C 函数调用,这导致了 Python 函数调用会消耗 C 的调用栈。而在 Python 3.11 中,在发生 Python 函数调用时,在创建一个新的 Frame 后,会「跳转」到解释器的开始,而不是创建一个新的 C 函数调用。这里的「跳转」在代码实现中就是一个 goto (opens new window)。
- 特化的自适应解释器(PEP 659: Specializing Adaptive Interpreter (opens new window)),从标题就可以看出,这是本文要描述的重点,那么我们接下来逐渐展开吧~
# 指令特化
特化是一种常见的 JIT 加速手段,对于动态语言而言,每一条看似简单的指令都可能对应着多种不同的实现,比如一个简简单单的 +(BINARY_ADD,在 Python 3.11 则是 BINARY_OP +),对于不同的类型,其实现是完全不同的,可能是 int 加,可能是 float 加,甚至可能执行用户自定义的 __add__,而判断具体执行什么的过程则带来了不小的运行时开销。
虽然动态语言的查找是不可避免的,但是对于大多数字节码来说,其往往只对应了一种具体实现,比如 a.b + c,假如 a.b 和 c 都为 int,那么其实大概率其类型是不会变的,这被称为「类型稳定性」。虽然我们不能保证之后 a.b 和 c 类型不会变,但我们可以根据这个信息来决策之后优先选择 int 加这一实现,这便是特化的思想。
Python 3.11 在解释器中引入了特化的思想,不过值得注意的是其是在字节码层面进行的,而没有编译成机器码,因此并不是 JIT(见 Is there a JIT compiler? (opens new window)),但毫无疑问这借鉴了 JIT 的思想。
# 额外信息的存储——Inline Cache
特化需要运行时的统计信息,Python 3.11 将这些信息存储在字节码中,即为 Inline Cache。与 Python 3.10 不同,Python 3.11 的字节码序列中为特化指令预留了 Inline Cache 的位置,比如 BINARY_OP 除去操作码和操作数 2 bytes 以外,还包含 2 bytes 的 Inline Cache,我们可以通过如下实验来验证:
import dis
def foo(a, b):
return a + b
dis.dis(foo)
# Output in Python 3.10
# 5 0 LOAD_FAST 0 (a)
# 2 LOAD_FAST 1 (b)
# 4 BINARY_ADD
# 6 RETURN_VALUE
# Output in Python 3.11
# 4 0 RESUME 0
#
# 5 2 LOAD_FAST 0 (a)
# 4 LOAD_FAST 1 (b)
# 6 BINARY_OP 0 (+)
# 10 RETURN_VALUE
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
可以看到 Python 3.10 每个字节码都占据 2 bytes,而 Python 3.11 中 BINARY_OP 则占据了 4 bytes,这其中就包含了 2 bytes 的 Inline Cache。
Python 3.11 全部的特化指令如下:
// https://github.com/python/cpython/blob/3.11/Include/internal/pycore_opcode.h#L41-L53
const uint8_t _PyOpcode_Caches[256] = {
[BINARY_SUBSCR] = 4,
[STORE_SUBSCR] = 1,
[UNPACK_SEQUENCE] = 1,
[STORE_ATTR] = 4,
[LOAD_ATTR] = 4,
[COMPARE_OP] = 2,
[LOAD_GLOBAL] = 5,
[BINARY_OP] = 1,
[LOAD_METHOD] = 10,
[PRECALL] = 1,
[CALL] = 4,
};
2
3
4
5
6
7
8
9
10
11
12
13
14
当然其实这里展示的是 CPython 各个指令的 Inline Cache 长度,Inline Cache 以 _Py_CODEUNIT 为基本单元,_Py_CODEUNIT 的大小则是 2 bytes,因此 BINARY_OP 对应的 1 即代表其 Inline Cache 大小为 2 bytes。再以 LOAD_ATTR 为例的话,其 Inline Cache 大小为 4*2=8 bytes,加上其本身共 10 bytes。
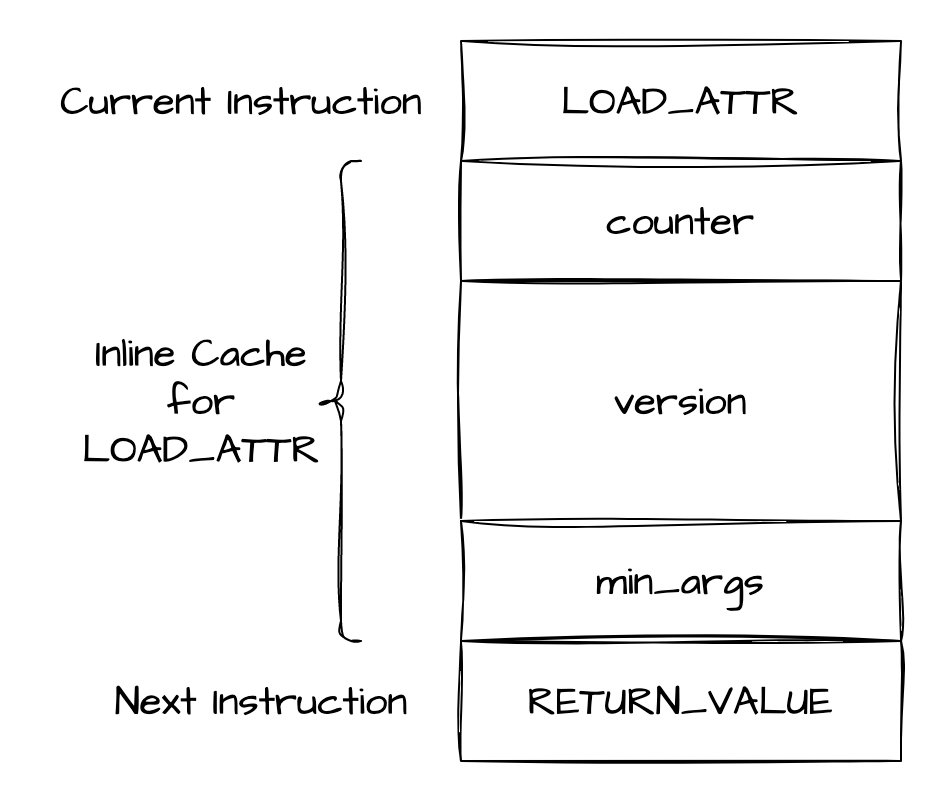
关于 Inline Cache 的数据结构我们也可以在 cpython 3.11 pycore_code.h (opens new window) 中找到,这里同样以 LOAD_ATTR 为例:
// https://github.com/python/cpython/blob/3.11/Include/internal/pycore_code.h#L55-L61
typedef struct {
_Py_CODEUNIT counter;
_Py_CODEUNIT version[2];
_Py_CODEUNIT index;
} _PyAttrCache;
#define INLINE_CACHE_ENTRIES_LOAD_ATTR CACHE_ENTRIES(_PyAttrCache)
2
3
4
5
6
7
8
可以看到它的 4 个 _Py_CODEUNIT 分别为 counter、version[2]、index,这里第一个字段固定表示计数器,对于所有特化指令是一致的,其它字段则视具体指令而定。
从字节码布局来看是这样的:
在编译结束阶段,CPython 会在 Inline Cache 的位置填充 0:
// https://github.com/python/cpython/blob/3.11/Python/compile.c#L205-L231
static void
write_instr(_Py_CODEUNIT *codestr, struct instr *instruction, int ilen)
{
// ...
while (caches--) {
*codestr++ = _Py_MAKECODEUNIT(CACHE, 0);
}
}
2
3
4
5
6
7
8
9
其中字节码 CACHE (opens new window) 对应的值也是 0,因此每个 _Py_CODEUNIT 相当于填充了 2 bytes 的 0。
因此在编译结束后的字节码其实看起来是这样子的:
4 0 RESUME 0
5 2 LOAD_FAST 0 (self)
4 LOAD_ATTR 0 (a)
6 (CACHE) 0
8 (CACHE) 0
10 (CACHE) 0
12 (CACHE) 0
14 RETURN_VALUE
2
3
4
5
6
7
8
9
这里 LOAD_ATTR 后紧紧跟随了独属于它的 4 个 Inline Cache,这些 Cache 会在运行时被填充。
# 字节码族——特化与自适应
为了实现特化,Python 3.11 在运行时会根据 Inline Cache 的信息来原位替换原有的字节码,不过替换的字节码必须是同一「族」(family)的。比如对于编译期产生的原始 LOAD_ATTR,该族包含如下几条指令:
- 原始指令:
LOAD_ATTR - 自适应指令:
LOAD_ATTR_ADAPTIVE - 特化指令:
LOAD_ATTR_INSTANCE_VALUE:一种常见的情况,其中属性存储在对象的值数组中,并且不被覆盖描述符遮蔽LOAD_ATTR_MODULE:从模块 load 属性LOAD_ATTR_SLOT:从__slots__加载属性
# 原始指令到自适应指令的转换
原始指令 LOAD_ATTR 仍然执行原来一样的操作,因此只执行原始指令是没有加速效果的,为了加速,Python 3.11 首先会将其替换成自适应指令 LOAD_ATTR_ADAPTIVE,这一步是在运行时 RESUME 指令做的,这也是 Python 3.11 函数第一条指令总是 RESUME 的原因
// https://github.com/python/cpython/blob/3.11/Python/ceval.c#L1776-L1779
TARGET(RESUME) {
_PyCode_Warmup(frame->f_code);
JUMP_TO_INSTRUCTION(RESUME_QUICK);
}
2
3
4
5
RESUME 指令会调用 _PyCode_Warmup 增加 warmup 计数器 co_warmup
// https://github.com/python/cpython/blob/3.11/Include/internal/pycore_code.h#L95-L111
#define QUICKENING_WARMUP_DELAY 8
/* We want to compare to zero for efficiency, so we offset values accordingly */
#define QUICKENING_INITIAL_WARMUP_VALUE (-QUICKENING_WARMUP_DELAY)
void _PyCode_Quicken(PyCodeObject *code);
static inline void
_PyCode_Warmup(PyCodeObject *code)
{
if (code->co_warmup != 0) {
code->co_warmup++;
if (code->co_warmup == 0) {
_PyCode_Quicken(code);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这里 co_warmup 初始值为 QUICKENING_INITIAL_WARMUP_VALUE 即 -8,也就是说在经过 8 次 RESUME 之后,co_warmup 会变为 0,这时候就会调用 _PyCode_Quicken 来进行加速。(这里只是简化说明,实际上不止 RESUME 会调用 _PyCode_Warmup)
// https://github.com/python/cpython/blob/3.11/Python/specialize.c#L258-L319
// Insert adaptive instructions and superinstructions. This cannot fail.
void
_PyCode_Quicken(PyCodeObject *code)
{
_Py_QuickenedCount++;
int previous_opcode = -1;
_Py_CODEUNIT *instructions = _PyCode_CODE(code);
for (int i = 0; i < Py_SIZE(code); i++) {
int opcode = _Py_OPCODE(instructions[i]);
uint8_t adaptive_opcode = _PyOpcode_Adaptive[opcode];
if (adaptive_opcode) {
_Py_SET_OPCODE(instructions[i], adaptive_opcode);
// Make sure the adaptive counter is zero:
assert(instructions[i + 1] == 0);
previous_opcode = -1;
i += _PyOpcode_Caches[opcode];
}
else {
assert(!_PyOpcode_Caches[opcode]);
switch (opcode) {
case EXTENDED_ARG:
_Py_SET_OPCODE(instructions[i], EXTENDED_ARG_QUICK);
break;
case JUMP_BACKWARD:
_Py_SET_OPCODE(instructions[i], JUMP_BACKWARD_QUICK);
break;
case RESUME:
_Py_SET_OPCODE(instructions[i], RESUME_QUICK);
break;
case LOAD_FAST:
switch(previous_opcode) {
case LOAD_FAST:
_Py_SET_OPCODE(instructions[i - 1],
LOAD_FAST__LOAD_FAST);
break;
case STORE_FAST:
_Py_SET_OPCODE(instructions[i - 1],
STORE_FAST__LOAD_FAST);
break;
case LOAD_CONST:
_Py_SET_OPCODE(instructions[i - 1],
LOAD_CONST__LOAD_FAST);
break;
}
break;
case STORE_FAST:
if (previous_opcode == STORE_FAST) {
_Py_SET_OPCODE(instructions[i - 1],
STORE_FAST__STORE_FAST);
}
break;
case LOAD_CONST:
if (previous_opcode == LOAD_FAST) {
_Py_SET_OPCODE(instructions[i - 1],
LOAD_FAST__LOAD_CONST);
}
break;
}
previous_opcode = opcode;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
这里算是一个小的「pass」,遍历全部字节码进行了替换:
- 如果该指令是可特化的,则将该指令替换为自适应版本,比如
LOAD_ATTR将会被原位替换为LOAD_ATTR_ADAPTIVE - 如果该指令是
EXTENDED_ARG、JUMP_BACKWARD、RESUME之一,则将其转为相应的 quick 版本,比如RESUME将会被原位替换为RESUME_QUICK - 如果该指令和下一条指令可以 combine 在一起,则这两条指令 combine 成一条超指令(super instruction),比如
LOAD_FAST+LOAD_FAST将会被原位替换为LOAD_FAST__LOAD_FAST
之后解释器再解释执行的就是自适应指令了。
# 自适应指令
仍然以 LOAD_ATTR 为例,其自适应指令 LOAD_ATTR_ADAPTIVE 的实现如下:
TARGET(LOAD_ATTR_ADAPTIVE) {
assert(cframe.use_tracing == 0);
_PyAttrCache *cache = (_PyAttrCache *)next_instr;
if (ADAPTIVE_COUNTER_IS_ZERO(cache)) {
PyObject *owner = TOP();
PyObject *name = GETITEM(names, oparg);
next_instr--;
if (_Py_Specialize_LoadAttr(owner, next_instr, name) < 0) {
next_instr++;
goto error;
}
DISPATCH_SAME_OPARG();
}
else {
STAT_INC(LOAD_ATTR, deferred);
DECREMENT_ADAPTIVE_COUNTER(cache);
JUMP_TO_INSTRUCTION(LOAD_ATTR);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这里两个分支分别表示
- 如果自适应计数器减到 0,则尝试调用
_Py_Specialize_LoadAttr进行特化 - 否则自适应计数器减 1(计数器字段 - 1,而不是整个数值 - 1),然后跳转到原始指令
LOAD_ATTR
自适应计数器字段与原始状态和特化状态并不相同,它的 16 bit 被分割成了两部分,其中高 12 bit 才是计数器(counter),低 4 bit 为回退指数(backoff exponent)。计数器总是会被初始化为 ,比如回退指数为 0 时,计数器初始值为 0,回退指数为 3 时,计数器初始值为 7,以此类推。(详见 cpython 3.11 pycore_code.h (opens new window))
下面我们看看 _Py_Specialize_LoadAttr 中实际发生了什么:
// https://github.com/python/cpython/blob/3.11/Python/specialize.c#L655-L755
int
_Py_Specialize_LoadAttr(PyObject *owner, _Py_CODEUNIT *instr, PyObject *name)
{
assert(_PyOpcode_Caches[LOAD_ATTR] == INLINE_CACHE_ENTRIES_LOAD_ATTR);
_PyAttrCache *cache = (_PyAttrCache *)(instr + 1);
if (PyModule_CheckExact(owner)) {
// LOAD_ATTR_MODULE 特化尝试
int err = specialize_module_load_attr(owner, instr, name, LOAD_ATTR,
LOAD_ATTR_MODULE);
if (err) {
goto fail;
}
goto success;
}
PyTypeObject *type = Py_TYPE(owner);
if (type->tp_dict == NULL) {
if (PyType_Ready(type) < 0) {
return -1;
}
}
PyObject *descr;
DescriptorClassification kind = analyze_descriptor(type, name, &descr, 0);
switch(kind) {
case OVERRIDING:
SPECIALIZATION_FAIL(LOAD_ATTR, SPEC_FAIL_ATTR_OVERRIDING_DESCRIPTOR);
goto fail;
case METHOD:
SPECIALIZATION_FAIL(LOAD_ATTR, SPEC_FAIL_ATTR_METHOD);
goto fail;
case PROPERTY:
SPECIALIZATION_FAIL(LOAD_ATTR, SPEC_FAIL_ATTR_PROPERTY);
goto fail;
case OBJECT_SLOT:
{
PyMemberDescrObject *member = (PyMemberDescrObject *)descr;
struct PyMemberDef *dmem = member->d_member;
Py_ssize_t offset = dmem->offset;
if (!PyObject_TypeCheck(owner, member->d_common.d_type)) {
SPECIALIZATION_FAIL(LOAD_ATTR, SPEC_FAIL_EXPECTED_ERROR);
goto fail;
}
if (dmem->flags & PY_AUDIT_READ) {
SPECIALIZATION_FAIL(LOAD_ATTR, SPEC_FAIL_ATTR_AUDITED_SLOT);
goto fail;
}
if (offset != (uint16_t)offset) {
SPECIALIZATION_FAIL(LOAD_ATTR, SPEC_FAIL_OUT_OF_RANGE);
goto fail;
}
assert(dmem->type == T_OBJECT_EX);
assert(offset > 0);
cache->index = (uint16_t)offset;
write_u32(cache->version, type->tp_version_tag);
// 特化 LOAD_ATTR 为 LOAD_ATTR_SLOT
_Py_SET_OPCODE(*instr, LOAD_ATTR_SLOT);
goto success;
}
case DUNDER_CLASS:
{
Py_ssize_t offset = offsetof(PyObject, ob_type);
assert(offset == (uint16_t)offset);
cache->index = (uint16_t)offset;
write_u32(cache->version, type->tp_version_tag);
// 特化 LOAD_ATTR 为 LOAD_ATTR_SLOT
_Py_SET_OPCODE(*instr, LOAD_ATTR_SLOT);
goto success;
}
case OTHER_SLOT:
SPECIALIZATION_FAIL(LOAD_ATTR, SPEC_FAIL_ATTR_NON_OBJECT_SLOT);
goto fail;
case MUTABLE:
SPECIALIZATION_FAIL(LOAD_ATTR, SPEC_FAIL_ATTR_MUTABLE_CLASS);
goto fail;
case GETSET_OVERRIDDEN:
SPECIALIZATION_FAIL(LOAD_ATTR, SPEC_FAIL_OVERRIDDEN);
goto fail;
case BUILTIN_CLASSMETHOD:
case PYTHON_CLASSMETHOD:
case NON_OVERRIDING:
case NON_DESCRIPTOR:
case ABSENT:
break;
}
// LOAD_ATTR_INSTANCE_VALUE 特化尝试
int err = specialize_dict_access(
owner, instr, type, kind, name,
LOAD_ATTR, LOAD_ATTR_INSTANCE_VALUE, LOAD_ATTR_WITH_HINT
);
if (err < 0) {
return -1;
}
if (err) {
goto success;
}
fail:
STAT_INC(LOAD_ATTR, failure);
assert(!PyErr_Occurred());
cache->counter = adaptive_counter_backoff(cache->counter); // backoff + 1,根据 backoff 重设 counter
return 0;
success:
STAT_INC(LOAD_ATTR, success);
assert(!PyErr_Occurred());
cache->counter = miss_counter_start(); // 特化成功,设置特化计数器初始值(53)
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
这里有几处 _Py_SET_OPCODE 即是特化成功时将当前指令替换为特化指令的逻辑。我们注意一下 fail 和 success,即特化失败和特化成功的返回逻辑:
- 如果发生特化失败,则会将
backoff+ 1,并根据其设置计数器的初始值,显然失败次数越多,计数器初始值越大,就越不容易触发特化,从而有效避免了频繁触发特化失败。 - 如果特化成功,此时指令已经被替换成相应的特化指令,此时会将计数器设置为特化计数器初始值
53,该值来源见 cpython 3.11 specialize.c - miss_counter_start (opens new window)(简单说就是 cpython 团队发现 50 左右是一个合适的值,就在 50 左右找了一个合适的质数)
注意从 RESUME warmup 得来的计数器本就是 0,因此自适应指令最开始就会尝试特化,而没有额外的 warmup 过程。而从特化指令发生去优化(de-optimization)退化为自适应指令时,则会设置一个适中的初始值 31(,见 cpython 3.11 pycore_code.h - adaptive_counter_start (opens new window)),以免频繁发生去优化。
# 特化指令的执行逻辑
这里以 LOAD_ATTR_INSTANCE_VALUE 为例看一下特化指令的执行逻辑:
// https://github.com/python/cpython/blob/3.11/Python/ceval.c#L1489
#define DEOPT_IF(cond, instname) if (cond) { goto miss; }
// https://github.com/python/cpython/blob/3.11/Python/ceval.c#L3496-L3517
TARGET(LOAD_ATTR_INSTANCE_VALUE) {
assert(cframe.use_tracing == 0);
PyObject *owner = TOP();
PyObject *res;
PyTypeObject *tp = Py_TYPE(owner);
_PyAttrCache *cache = (_PyAttrCache *)next_instr;
uint32_t type_version = read_u32(cache->version);
assert(type_version != 0);
DEOPT_IF(tp->tp_version_tag != type_version, LOAD_ATTR);
assert(tp->tp_dictoffset < 0);
assert(tp->tp_flags & Py_TPFLAGS_MANAGED_DICT);
PyDictValues *values = *_PyObject_ValuesPointer(owner);
DEOPT_IF(values == NULL, LOAD_ATTR);
res = values->values[cache->index];
DEOPT_IF(res == NULL, LOAD_ATTR);
STAT_INC(LOAD_ATTR, hit);
Py_INCREF(res);
SET_TOP(res);
Py_DECREF(owner);
JUMPBY(INLINE_CACHE_ENTRIES_LOAD_ATTR);
DISPATCH();
}
// https://github.com/python/cpython/blob/3.11/Python/ceval.c#L5701-L5720
/* Specialization misses */
miss:
{
STAT_INC(opcode, miss);
opcode = _PyOpcode_Deopt[opcode];
STAT_INC(opcode, miss);
/* The counter is always the first cache entry: */
_Py_CODEUNIT *counter = (_Py_CODEUNIT *)next_instr;
*counter -= 1;
if (*counter == 0) {
int adaptive_opcode = _PyOpcode_Adaptive[opcode];
assert(adaptive_opcode);
_Py_SET_OPCODE(next_instr[-1], adaptive_opcode);
STAT_INC(opcode, deopt);
*counter = adaptive_counter_start();
}
next_instr--;
DISPATCH_GOTO();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
这里出现了几次 DEOPT_IF,即去优化逻辑,如果并不满足当前特化逻辑时,将会将计数器 - 1,并执行原始指令。当计数器减到 0 时,会将当前指令替换为自适应指令,并重置计数器为初始值(即上面提到的 31)。
# 指令特化流程回顾
至此,整个「原始指令」→「自适应指令」↔「特化指令」的转换关系基本清晰了~现在我们总结回顾下~
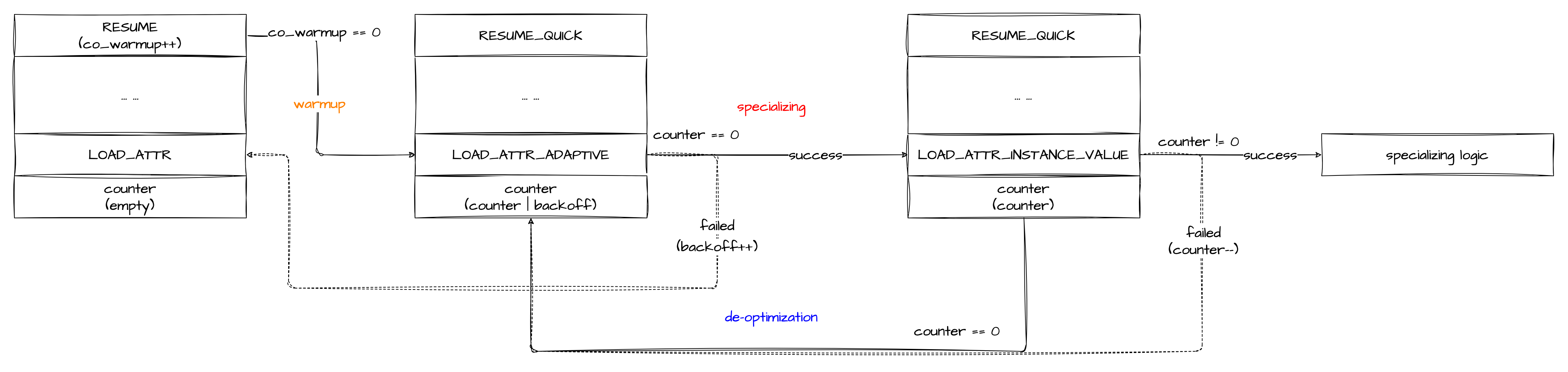
值得注意的是,其中的虚线表示字节码层面不变,只是逻辑上 fallback 到原始指令 / 自适应指令,而实线则是代表字节码发生了原位替换,即图中的「warmup」、「specializing」、「de-optimization」
# Faster CPython 的未来
PEP 659 为 Faster CPython 做了一个良好的开端,它让我们看到了 CPython 在利用非 JIT 的方式在运行时获得更多的加速,Faster CPython 目前也在做着更多的改进:
- 更多的指令特化,Python 3.12 已经实现了一个 DSL (opens new window),用来方便实现解释器逻辑(
ceval.c),新的解释器逻辑使用 DSL 写在了 bytecodes.c (opens new window),之后会根据其编译成 generated_cases.c.h (opens new window)(就是原来ceval.c里的非常大的 switch-case),可以更加方便地编写指令特化、去优化、超指令等逻辑 - 第二层优化器(Tier 2 Optimizer for CPython -- Early design (opens new window)),该提案基于第一层优化器,即本文所述的 PEP 659,本文所述的优化器仅仅会针对单条指令,而 Tier 2 Optimizer 则会考虑更大的优化范围,将会为未来构建 JIT 提供坚实的基础
- 等等……(其他的我暂时还不清楚)
那么暂时先这样啦,以后有什么新的有趣的优化再整理~一些关于 Python 3.11 其他改动的适配文档已经在之前整理在了 PaddleSOT/docs/compat/python311 (opens new window),有兴趣也可以参考下~
# References
- PEP 659 – Specializing Adaptive Interpreter (opens new window)
- CPython 3.11 Source (opens new window)
- Faster CPython Ideas (opens new window)
- The Bytecode Interpreter (3.11) (opens new window)
- Adding or extending a family of adaptive instructions (opens new window)
- How we are making Python 3.11 faster (CPython project) (opens new window)